Besides an ATM researcher, I am also serving as the CTO of FinCatch, a startup backed by Hong Kong Science and Technology Park (HKSTP) and Google's Incubation Program. While building our product, we discovered nano-graphrag, which quickly became a crucial component in our pipeline for transforming unstructured data into structured information.
I've been impressed with this tool that I wanted to share my experience with it. In this blog post, I'll walk you through what makes nano-graphrag special and how it might help with your own data challenges.
What is nano-graphrag?
Nano-graphrag is a lightweight alternative to Microsoft's GraphRAG framework. It maintains all the essential functionality while being:
- Simple - with clean, readable code that's easy to understand
- Fast - performing efficiently without excessive resource requirements
- Hackable - designed to be modified and adapted to specific use cases
Nano-graphrag lies in its ability to deliver the power of knowledge graph-enhanced retrieval without the complexity of larger implementations. Whether you're building information retrieval systems or trying to make sense of document collections, this tool offers an accessible entry point to graph-based RAG techniques.
"GraphRAG is an enhancement to traditional Retrieval Augmented Generation (RAG) that uses a knowledge graph to represent relationships between entities found in documents. Unlike traditional RAG, which treats documents as independent units, GraphRAG understands the connections between information pieces, enabling more contextually relevant and comprehensive responses."
Core Components
In this section, I will briefly introduce the key components of nano-graphrag, including entity extraction and query processing.
Entity Extraction
Entity extraction is a core component of the nano-graphrag system that processes input text to identify entities and their relationships. This component creates the knowledge graph foundation that enables graph-based retrieval enhancements over traditional RAG systems. The system automatically extracts named entities, categorizes them according to types, and establishes relationships between them, using LLM capabilities. At its core, entity extraction converts raw text into structured knowledge by identifying important entities and mapping the relationships between them. This creates a foundation for graph-based retrieval that significantly enhances traditional RAG approaches.
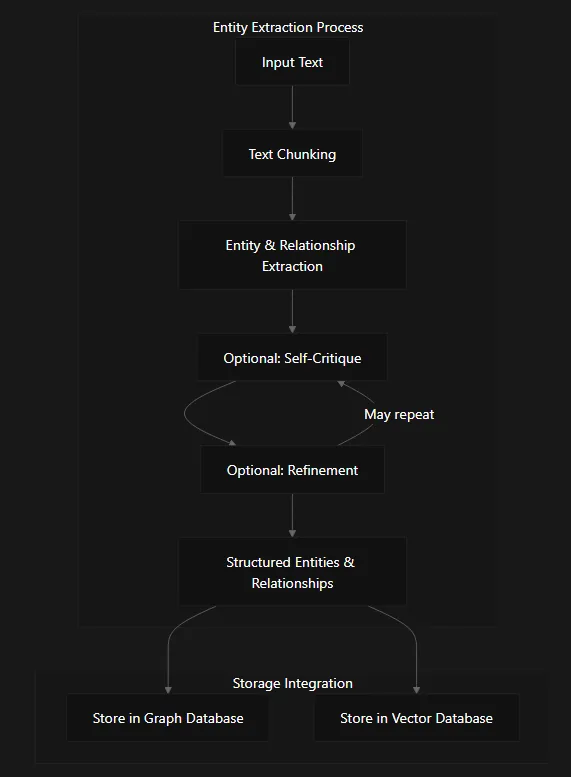
Fig 1: Entity extraction in nano-graphrag
The process works like this:
- Text Input & Chunking: The system breaks down documents into manageable chunks
- Entity & Relationship Extraction: Using Large Language Models (LLMs) through the DSPy framework, the system identifies entities and connections between them
- Optional Self-Critique: The system can evaluate its own extraction quality
- Optional Refinement: Based on the critique, extractions can be improved
- Storage: The structured data populates both graph and vector databases
Consider this simple example:
Input: "Apple announced a new iPhone model."
Extracted Entities:
1. APPLE (ORGANIZATION)
2. IPHONE (PRODUCT)
Extracted Relationship:
APPLE → IPHONE (manufactures)This seemingly simple extraction creates the building blocks for a knowledge graph that can answer complex queries like "Which companies manufacture smartphones?" – something traditional keyword-based RAG would struggle with.
The Data Models Behind the Scene
Entity Model
Each entity extracted by the system includes:
- entity_name: The identifier (e.g., "Apple Inc.")
- entity_type: Category from a comprehensive taxonomy (e.g., "ORGANIZATION")
- description: Detailed information about the entity
- importance_score: A value (0-1) indicating significance
Relationship Model
Relationships capture connections between entities:
- src_id & tgt_id: Source and target entity names
- description: Details about the relationship
- weight: Strength of the connection (0-1)
- order: Relationship proximity (1=direct, 2=second-order, 3=third-order)
Query processing
nano-graphrag offers three distinct query modes, each with its own approach to information retrieval:
Naive Search: The Traditional Approach
Naive search operates like traditional vector search systems. When a query comes in:
- The system performs a vector similarity search against a database of text chunks
- It retrieves the most relevant chunks based on semantic similarity
- These chunks are formatted into a context and sent to a language model
- The LLM then generates a response based on the retrieved information
This approach works well for straightforward factual queries but lacks the contextual awareness that more sophisticated methods provide.
Local Search: Entity-Centered Exploration
Local search takes query processing a step further by leveraging the relationships between entities:
- First, it identifies entities in the query using vector similarity search
- It then explores the neighborhood of these entities in the knowledge graph
- The system gathers related communities, text units, and relationships
- All this information is organized into a structured context with clear sections
- The LLM uses this rich, structured context to generate a more informed response
This mode excels at answering questions about specific entities and their relationships, providing precise, contextually relevant information.
Global Search: Community-Based Synthesis
For broader, more thematic questions, Global search takes a high-level approach:
- It retrieves community schemas from the knowledge graph
- Communities are sorted by occurrence and filtered by level
- The system extracts the most relevant points from community reports
- These points are combined and formatted into a comprehensive context
- The LLM synthesizes this information to provide a high-level response
This approach is particularly effective for handling large knowledge graphs and identifying patterns or themes that might not be apparent at the entity level.
Choosing the Right Query Mode
Each query mode has its strengths and ideal use cases:
| Query Mode | Best For | Strengths | Limitations | | --- | --- | --- | --- | | Naive | Simple factual queries | Simple implementation, faster with small collections | Limited context awareness | | Local | Entity-specific questions, relationship queries | Better precision on entity-related queries, leverages graph structure | May miss global patterns or themes | | Global | Thematic analysis, pattern discovery | Better for high-level questions | Less precise for specific entity details |
For most use cases, the local mode offers a good balance between precision and contextual understanding. Global mode shines with large knowledge graphs and high-level analytical questions, while naive mode serves as a reliable baseline for simpler queries.
Quick Start
For a detail QuickStart tutorial, please refer to here, the original readme of nano-graphrag.
Conclusion
Nano-graphrag enhances traditional RAG systems by integrating knowledge graphs with LLMs. This framework provides a flexible approach to information retrieval and processing.
The three query modes (Naive, Local, and Global) enable different levels of analysis, from basic fact retrieval to complex relationship exploration. Each mode is optimized for specific use cases, allowing for efficient query processing across various scenarios.
Nano-graphrag serves as an effective bridge between structured knowledge representations and natural language processing. Its lightweight implementation offers powerful capabilities without excessive computational requirements.
By leveraging the relationship structures within data, nano-graphrag produces responses that demonstrate improved contextual awareness and relevance compared to standard vector-based retrieval methods.